Dzisiaj odpowiem na pytanie, co w mojej opinii oznacza stwierdzenie – „SQL na poziomie zaawansowanym”. Kiedy możesz określić siebie jako osobę posługującą się językiem SQL na takim poziomie.
Może zdarzyła Ci się sytuacja, kiedy ktoś zapytał Cię, na przykład na rozmowie rekrutacyjnej, jak oceniasz swoje umiejętności z SQL? I jak wtedy odpowiedziałaś/eś? Jesteś w stanie obiektywnie ocenić, na jakim poziomie są twoje umiejętności z baz danych i SQL? Często samemu trudno się sklasyfikować. Dlatego powstał ten wpis, aby pomóc Ci zrozumieć, na jakim poziomie zaawansowania z SQL jesteś.
Poniższe wyznaczniki poziomów powstały nie tylko na podstawie mojej intuicji i doświadczenia. Zasięgnęłam opinii koleżanek i kolegów, którzy przeprowadzają rozmowy techniczne podczas rekrutacji. Ich opinie zderzyłam z tym, co oferują kursy i książki z SQL, poziom zaawansowany. Finalnie przypomniałam sobie, jakie umiejętności sprawdzają dawne certyfikaty z T-SQL.
Na tej podstawie powstał wpis o klasyfikacji zaawansowania języka SQL (w kontekście SQL Server). Skupiam się na użyciu SQL w kontekście analitycznym. Z perspektywy administratora baz danych klasyfikacja będzie wyglądać nieco inaczej. Bardziej skupia się na zagadnieniach modyfikacji baz, struktur, zarządzaniami uprawnień etc.
Adnotacja: Znasz Efekt Dunninga-Krugera ? Jeżeli nie, to zaraz Ci wytłumaczę, o co w nim chodzi. Zdarzyło Ci się myśleć, podczas nauki jakiegoś zagadnienia, że wiesz już większość z danej dziedziny? Idziesz dalej w nauce, a potem to uczucie zamienia się w strach, że to jest skomplikowane i jednak nic nie wiesz? :) To w skrócie jest efekt Dunninga- Krugera. Polega on na tym, że osoby początkujące w jakieś dziedzinie (na przykład początkujący użytkownicy SQL) mają tendencję do przeceniania swoich umiejętności. Natomiast osoby, o dużych umiejętnościach w danej dziedzinie mają tendencję do zaniżania swoich osiągnięć. Dlatego sięgnij po ten wpis i dowiedz się obiektywnie, na jakim etapie zaawansowania SQL jesteś!
Moje ulubione zagadnienia opisałam szczegółowo, resztę tematów (jeżeli jeszcze (!) ich nie znasz) znajdziesz w dokumentacji SQL Server lub na blogach.
SQL Zaawansowany, czy to potrafisz?
- Procedury składowane i funkcje własne.
- Polecenie MERGE.
- Triggers – Wyzwalacze.
- Obiekty tymczasowe.
- Kursory.
- Funkcja PIVOT i UNPIVOT
- Rekurencja w CTE
- SQL dynamiczny
- Wyciągnie delty, czyli funkcje LEAD() i LAG()
- Running Totals, np. suma krocząca
- Optymalizacja zapytań
- Tworzenie indeksów
- Tworzenie kluczy głównych i obcych
- Constraint w tabelach
- Plany zapytań
- Full text searching
- Poziomy izolacji transakcji
- Szukanie wzorców – ROW PATTERN RECOGNITION
Procedury składowane i funkcje własne.
Pisanie swoich procedur i funkcji to zagadnienie, które trzeba opanować nawet na poziomie średnio-zaawansowanym. Piszesz swoje własne funkcje i potrafisz je wywoływać? Czy procedury, które tworzysz, posiadają parametry i można je wywoływać z różnymi wartościami? Jeżeli tak, to ok ! Podam Ci teraz parę przykładów, do czego najczęściej wykorzystywane są procedury składowane i funkcje w SQL.
Procedur możesz użyć do:
- dodania nowych danych do tabel,
- uzyskania danych historycznych w tabeli,
- dodania pól informujących o datach obowiązywania danego rekordu w tabeli na bazie,
- otrzymania najnowszych danych z bazy.
Funkcje użyjesz w SQL do:
- czyszczenia danych na bazie,
- modyfikacji danych, na przykład wykonanie określonych zmian w rekordach, tak aby dane były bardziej czytelne,
- sprawdzenia poprawności rekordów w bazie.
Jak wygląda składnia procedur, a jak funkcji?
Prosta procedura, która pokazuje Id bazy danych, bazując na nazwie bazy. Możesz zauważyć, że procedura ma jeden parametr.

Wywołanie takiej procedury, wygląda następująco (pamiętaj, że musisz użyć parametru):
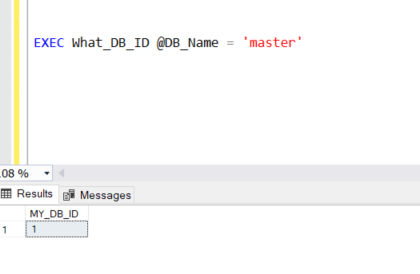
Polecenie MERGE.
MERGE w SQL Server pomoże Ci zapanować nad aktualizacją danych w tabelach. Jest to zagadnienie, które często pojawia się podczas rozmów rekrutacyjnych. Podstawowym przypadkiem użycia tego polecenia, jest synchronizacja danych w tabeli. Dane są dodawane do tabeli, bądź aktualizowane lub usuwane, bazując na różnicach pomiędzy tabelą wyjściową a tabelą, do której się porównujemy.
Zobacz, jak wygląda składnia tego polecenia. Źródło.
-- SQL Server and Azure SQL Database
[ WITH <common_table_expression> [,...n] ]
MERGE
[ TOP ( expression ) [ PERCENT ] ]
[ INTO ] <target_table> [ WITH ( <merge_hint> ) ] [ [ AS ] table_alias ]
USING <table_source> [ [ AS ] table_alias ]
ON <merge_search_condition>
[ WHEN MATCHED [ AND <clause_search_condition> ]
THEN <merge_matched> ] [ ...n ]
[ WHEN NOT MATCHED [ BY TARGET ] [ AND <clause_search_condition> ]
THEN <merge_not_matched> ]
[ WHEN NOT MATCHED BY SOURCE [ AND <clause_search_condition> ]
THEN <merge_matched> ] [ ...n ]
[ <output_clause> ]
[ OPTION ( <query_hint> [ ,...n ] ) ]
;
<target_table> ::=
{
[ database_name . schema_name . | schema_name . ]
target_table
}
<merge_hint>::=
{
{ [ <table_hint_limited> [ ,...n ] ]
[ [ , ] INDEX ( index_val [ ,...n ] ) ] }
}
<merge_search_condition> ::=
<search_condition>
<merge_matched>::=
{ UPDATE SET <set_clause> | DELETE }
<merge_not_matched>::=
{
INSERT [ ( column_list ) ]
{ VALUES ( values_list )
| DEFAULT VALUES }
}
<clause_search_condition> ::=
<search_condition>
Trigery – Triggers (Wyzwalacze).
Wyzwalacze, czyli po prostu Triggers, są to procedury, które są automatycznie wywoływane, po nastąpieniu danego zdarzenia. Procedura jest wyzwalana, jeżeli na bazie danych zajdzie określone zdarzenie. Może być to dodanie nowych rekordów w danej tabeli, może być to usunięcie obiektu na bazie. Wyzwalacze pozwolą Ci na większą kontrolę bazy danych, szczególnie jeżeli wielu użytkowników ma pozwolenie na modyfikację jej struktur.
Zobacz przykładowy wyzwalacz, który nie pozwala na nieumyślne usunięcie tabeli na bazie.

Przykłady użycia Wyzwalaczy w SQL Server:
- rejestrowanie zmian, które wydarzyły się w bazie danych,
- prewencja zmian w schemacie bazy danych.
Obiekty tymczasowe (np. tabele, procedury).
Tworzenie obiektów, które „żyją” tylko w obrębie sesji jest istotne dla wszystkich analityków, którzy używają SQL. Znasz różnicę między tabelą tymczasową #temptable a tabelą tymczasową ##temptable ?
Ta pierwsza będzie dostępna tylko w obrębie sesji, która je utworzyła. Zostanie usunięta po zamknięciu tej sesji. Drugi przykład, tabela ##temptable będzie dostępna dla wszystkich sesji, ale zostanie usunięta, jeżeli sesja na której została utworzona zostanie zamknięta.
Warto znać! Temat często omawiany na rekrutacjach.
Kursory
Kursory, czyli struktury pozwalające na pobieranie wyników zapytań. Użyj kursora do pobierania rekordów z bazy, po więcej niż jednym na raz. Należy uważać, ponieważ kursory potrafią zabrać sporo zasobów, czyli spowolnić bazę danych.
Pamiętaj, ze kursory mogą być jawne, bądź niejawne (IMPLICIT, EXPLICIT). Jedne tworzone są automatycznie podczas wykonywania zapytania SELECT, a drugie muszę być zdefiniowane przez użytkownika.
Funkcja PIVOT i UNPIVOT
Obie wyżej wymienione funkcje są bardzo istotne dla wszystkich osób analizujących dane na bazie. Dzięki PIVOT i UNPIVOT jesteś w stanie zamienić wiersze tabeli na kolumny, oraz odwrotnie (UNPIVOT) przemienić kolumny tabeli, z powrotem na wiersze.
Rekurencja w CTE
SQL dynamiczny
Wyciągnie delty, czyli funkcje LEAD() i LAG()
Running Totals, np. suma krocząca
Optymalizacja zapytań
Tworzenie indeksów
Tworzenie kluczy głównych i obcych.
Constraint w tabelach.
Plany zapytań
Full text searching
Poziomy izolacji transakcji
Szukanie wzorców – ROW PATTERN RECOGNITION
Słowo na koniec
Przede wszystkim musisz umieć pozyskać wiedzę na dany temat. Nie musisz od razu płynnie pisać pętli, ale musisz wiedzieć, że takie coś jak pętla istnieje. Nawet więcej, powinieneś wiedzieć, że w danym przypadku możesz użyć pętli. Świadomość narzędzi, jakie są dostępne, to jedna z ważniejszych cech, które ułatwią Ci pracę nie tylko z SQL, ale także w IT.